

 1. Introduction
1. Introduction
This guide provides a detailed step-by-step explanation of how to use a training dataset in PyTorch for AI/ML model training, focusing on HDF5 (.h5) files. It explains how to process, load and train a model using such datasets efficiently. HDF5 files are widely used for storing large scale datasets because they offer structured storage, fast access to data, and efficient handling of large files. PyTorch provides powerful tools to load and process these datasets for model training.
![]() 2. Understanding the Training Dataset
2. Understanding the Training Dataset
Before training an AI/ML model, it is essential to understand the structure and format of the dataset.
![]() 2.1 What is a Training Dataset?
2.1 What is a Training Dataset?
- A training dataset is a collection of data used to teach an AI model to recognize patterns.
- It contains input features and labels.
- Images are used as input, and labels also known as masks indicate regions of interest.
![]() 2.2 Understanding the Dataset Structure
2.2 Understanding the Dataset Structure
The dataset includes four main types of files:
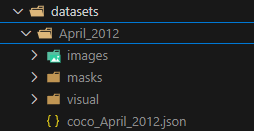
Dataset Structure
- Images Folder (images/):
- Contains the raw images used for training.
- The images are typically in standard formats such as JPEG.
- Each image represents solar data captured at a specific wavelength.

Raw Image used for Training

Colored Image
- Masks Folder (masks/):
- Contains segmentation masks for each image.
- These masks identify specific regions such as coronal holes in the images.
- Each mask is aligned with its corresponding image, meaning they share the same dimensions.

Mask
- Visuals Folder (visual/):
- Stores processed versions of the original images.
- These may be cropped, enhanced, or preprocessed to help visualize labeled regions.

Visual Image
- JSON Metadata File (.json):
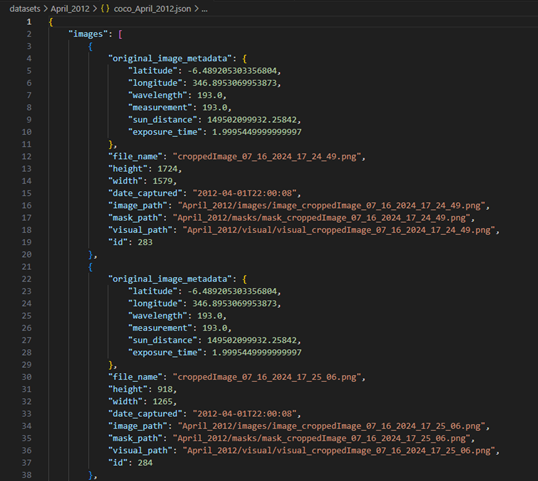
.jason File
Stores metadata related to the dataset, including:
- File paths for images, masks, and visuals.
- Label information, such as object categories.
- Scientific details, including latitude, longitude, exposure time, and wavelength of the captured images.
Helps automate the data loading process and ensures the correct matching of images and masks.
![]() 3. Using PyTorch to Load the Training Dataset
3. Using PyTorch to Load the Training Dataset
In PyTorch, datasets are handled using the Dataset and DataLoader classes, which enable efficient data loading and batch processing.
![]() 3.1 Extracting Image and Mask Paths from JSON
3.1 Extracting Image and Mask Paths from JSON
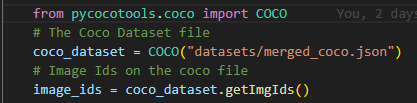
Image and Mask Paths from Jason
- The JSON file acts as an index for the dataset, linking images to their corresponding masks.
- In PyTorch, the file paths are extracted and stored so that they can be accessed during training.
![]() 3.2 Converting Images and Masks to Tensors
3.2 Converting Images and Masks to Tensors
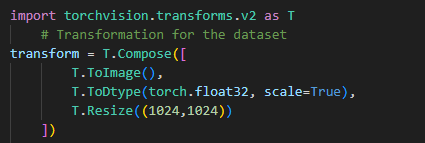
Converting Images and Masks to Tensors
- PyTorch models require input data to be in the form of tensors.
- The images and masks are converted into PyTorch tensors before being used in training.
- Normalization is applied to ensure the pixel values are within a suitable range.
![]() 3.3 Resizing and Augmenting the Dataset
3.3 Resizing and Augmenting the Dataset

Resizing and Augmenting the Dataset
- Images and masks may need to be resized to a fixed size (e.g., 1024×1024 pixels).
- Data augmentation techniques (such as flipping, rotation, or brightness adjustments) improve model performance by increasing variability in training data.
- PyTorch’s torchvision.transforms provides built-in functions for resizing, normalizing, and augmenting datasets.
![]() 4. Creating a Data Pipeline in PyTorch
4. Creating a Data Pipeline in PyTorch
![]() 4.1 Custom Dataset Class
4.1 Custom Dataset Class
PyTorch allows users to define a custom dataset class that reads images and masks from their respective folders.
- This dataset class ensures that each image is correctly paired with its corresponding mask.
![]() 4.2 Using a PyTorch DataLoader
4.2 Using a PyTorch DataLoader
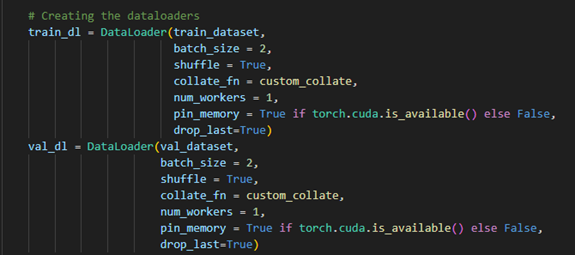
Creating the Dataloader
- The DataLoader class in PyTorch:
- Loads the dataset in batches instead of all at once.
- Uses shuffle operations to prevent overfitting.
- Supports parallel data loading to speed up training.
- The dataset is split into:
- Training set which is used to teach the model.
- Validation set which is used to check performance on unseen data.
![]() 5. Training an AI/ML Model in PyTorch
5. Training an AI/ML Model in PyTorch
![]() 5.1 Understanding the Training Process
5.1 Understanding the Training Process
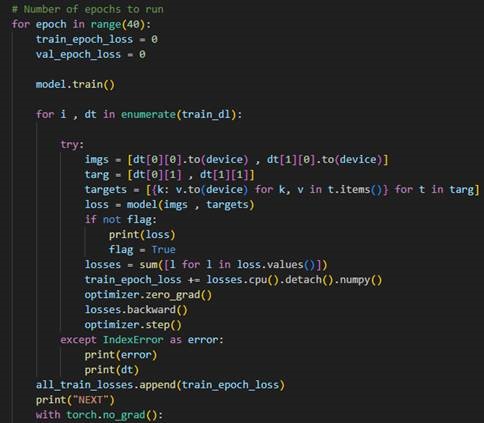
Training the model for 40 epoch
- The model is trained using mini-batches of images and masks.
- The images are passed through the model, and predictions are generated.
- The predictions are compared with the actual masks using a loss function.
- The optimizer adjusts the model parameters based on the loss to improve accuracy.
![]() 5.2 Selecting a Loss Function
5.2 Selecting a Loss Function
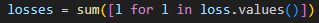
Loss function
- In PyTorch, different loss functions are used depending on the task:
- Binary Cross-Entropy Loss: Used for binary segmentation tasks.
- The loss function calculates the error between the predicted mask and the ground truth mask.
![]() 5.3 Choosing an Optimizer
5.3 Choosing an Optimizer
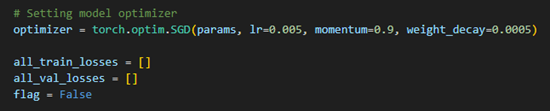
Setting Model Optimizer
- The optimizer updates the model’s weights to minimize loss.
- Adam or SGD Optimizer is commonly used because it automatically adjusts the learning rate.
- Learning rate schedulers can also be applied to adjust learning rates dynamically.
![]() 5.4 Running the Training Loop
5.4 Running the Training Loop
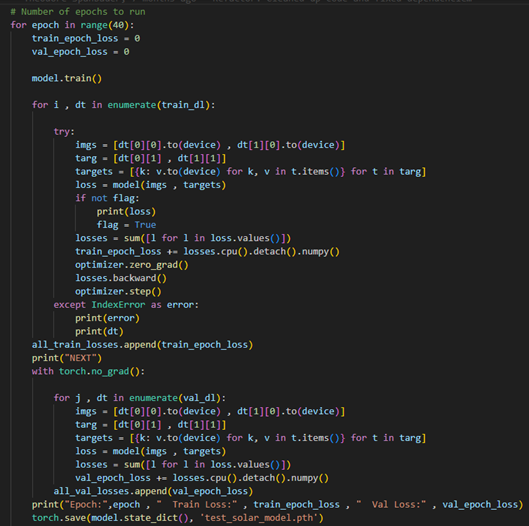
Training Loop
- The dataset is fed into the model in batches.
- The model predicts segmentation masks for each batch.
- The loss function computes the error, and the optimizer updates the model’s parameters.
- This process is repeated for multiple epochs until the model improves.
![]() 6. Evaluating the Model
6. Evaluating the Model
After training, the model’s performance is tested on new, unseen images.
![]() 6.1 Running the Model on Test Data
6.1 Running the Model on Test Data
Testing the model
- The trained model is used to generate predictions on test images.
- The predicted segmentation masks are compared with the actual masks.
![]() 6.2 Avoiding Overfitting
6.2 Avoiding Overfitting
- If the model performs well on training data but poorly on test data, it is overfitting.
Solutions include:
- Adding more training data.
- Applying data augmentation.
![]() 6.3 Saving and Using the Trained Model
6.3 Saving and Using the Trained Model

Saving the Trained Model
After training, the trained model is saved so it can be reused.
![]() 7. Predicting with a Trained Model
7. Predicting with a Trained Model
You can include these points in the Prediction section of your guide:
Loading the Trained Model
- The trained Mask R-CNN model is loaded using torch.load(), ensuring that it is in evaluation mode (model.eval()).
- The model is transferred to the appropriate device (CPU/GPU) for inference.
Preparing Input Data for Prediction
- Images need to be preprocessed using the same transformation steps as during training (resizing, normalization, tensor conversion).
- The image is passed through the model inside a torch.no_grad() block to disable gradient calculations, improving efficiency.
Generating Predictions
- The model outputs bounding boxes, labels, and segmentation masks for detected objects.
- The predicted masks contain pixel-wise probability values, where higher values indicate stronger predictions.
Visualizing Predictions
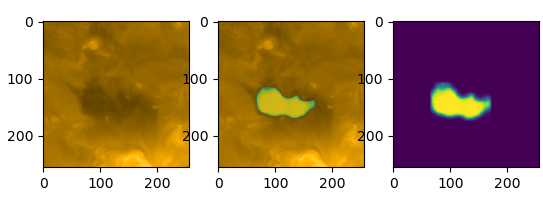
Coronal hole detected by the model
- The predicted segmentation masks can be overlayed on the original images to evaluate how well the model identifies regions of interest.
- The detected region in the middle and right images suggests that the model has identified a coronal hole.
- The segmentation mask highlights the area of interest in bright colors, indicating the detected region.